快速应用
大约 3 分钟
快速应用
Flink程序是延迟计算,只有最后调用execute()方法时才会真正触发执行程序
Flink程序开发的流程:
- 获取一个执行环境
- 加载/创建初始化数据
- 指定数据操作的算子
- 指定结果数据存放位置
- 调用execute()触发程序执行
1. 统计一个文件中各个单词出现的次数,把统计结果输出到文件
创建Maven项目,导入依赖
<dependencies>
<!--flink核心包-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.7.2</version>
</dependency>
<!--flink流处理包-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.7.2</version>
<scope>provided</scope>
</dependency>
<!--flink clients-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>1.7.2</version>
</dependency>
</dependencies>
单词统计(批数据处理)
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
/**
* 单词统计(批数据处理)
*/
public class WordCountBatch {
public static void main(String[] args) throws Exception {
String inputPath = "/Users/swd/logs/flink/input.txt";
String outputPath = "/Users/swd/logs/flink/output";
// 1. 获取Flink执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 2. 用Flink的运行环境,读取文件内容(待分析数据)
DataSource<String> lines = env.readTextFile(inputPath);
// 3. 对数据进行处理
DataSet<Tuple2<String, Integer>> dataSet = lines
// 将每一行数据进行映射转换
.flatMap(new SplitLine())
// 把相同的单词聚合到一起,Tuple(word,1),0表示word
.groupBy(0)
// 累加,field:1表示1号的field,即1
.sum(1);
// 4. 保存处理结果
dataSet.writeAsText(outputPath);
// 5. 触发执行程序
env.execute("WordCount Batch Process");
}
/**
* 如hello world ,映射为 (hello,1) ,(world,1)
*/
static class SplitLine implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String line, Collector<Tuple2<String, Integer>> collector) throws Exception {
for (String word : line.split(" "))
collector.collect(new Tuple2<>(word, 1));
}
}
}
输入文件内容
$ cat /Users/swd/logs/flink/input.txt
hello world
hello word
hi you
hi everyone
i am fine
输出结果
$ tree /Users/swd/logs/flink/output
/Users/swd/logs/flink/output
├── 1
├── 2
├── 3
├── 4
├── 5
├── 6
├── 7
└── 8
0 directories, 8 files
$ vim -o 1 2 3 4 5 6 7 8
1
2
(am,1)
(you,1)
3
(world,1)
4
(hello,2)
5
6
(everyone,1)
(i,1)
(word,1)
7
(fine,1)
8
(hi,2)
2. 流数据的单词统计
使用Socket模拟实时发送单词,使用Flink实时接收单词,对指定时间窗口内(例如5秒)的数据进行聚合汇总,每隔1秒汇总计算一次,并把时间窗口内计算结果打印
使用nc(netcat)模拟,监听端口7777,命令如下:
$ nc -lk 7777
hello
world
单词统计(流式数据)
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
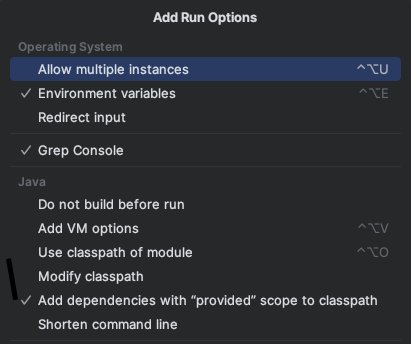
* 单词统计(流式数据)
* 需要勾选Java配置选项"provided",如下图
*/
public class WordCountStream {
public static void main(String[] args) throws Exception {
// 1. 获取Flink流执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 获取流式数据
DataStreamSource<String> dataStreamSource = env.socketTextStream("localhost", 7777);
// 3. 处理数据
DataStream<Tuple2<String, Integer>> dataStream = dataStreamSource
.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String line, Collector<Tuple2<String, Integer>> collector) throws Exception {
for (String word : line.split(" ")) {
collector.collect(Tuple2.of(word, 1));
}
}
})
.keyBy(0)
.sum(1);
// 4. 数据打印
dataStream.print();
// 5. 执行
env.execute("WordCount Stream Process");
}
}
输入数据
$ nc -lk 7777
hello
world
hello
world
hi
friend
输出数据(实时计算,打印在控制台)
3> (hello,1)
5> (world,1)
3> (hello,2)
5> (world,2)
3> (hi,1)
7> (friend,1)