MongoDB - 集群
MongoDB - 集群
1. 主从复制
4.0 后已弃用
主从架构中,master节点负责数据的读写,slave没有写入权限只能读取
在主从结构中,主节点的操作记录为oplog,它存储在系统该数据库local的oplog.$main集合中,这个集合的每个文档都代表主节点上执行的一个操作。从服务器会定期从主服务器获取oplog记录,然后在本机上执行。对于存储oplog的集合,Mongo采用固定集合,即新操作会覆盖旧操作。
由于没有自动故障转移,需要指定master和slave端,不推荐在生产中使用,且4.0后不再支持主从复制
2. 复制集 Replica Sets
复制集是由一组拥有相同数据集的mongod实例组成的集群,由2台或2台以上的服务器组成,以及复制集成员包括Primary主节点、Secondary从节点和投票节点。
复制集提供了数据的冗余备份,并在多个服务器上存储数据副本,提高了数据的可用性,保证数据的安全性。相比于主从多了自动切换的功能
2.1 为什么要使用复制集
- 高可用: 防止设备故障,提供自动failover功能
- 灾难恢复:发生故障时,可从其他节点恢复,用于备份
- 读写隔离: 可在备节点执行读,减少主库压力,如用于分析 报表 数据挖掘 系统任务等
2.2 复制集集群架构原理
原理和主从复制相同,
2.2.1 oplog具有幂等性,组成结构如下
{
"ts" : Timestamp(1446011584, 2),
"h" : NumberLong("1687359108795812092"),
"v" : 2,
"op" : "i",
"ns" : "test.nosql",
"o" : { "_id" : ObjectId("563062c0b085733f34ab4129"), "name" : "mongodb", "score" : "10"}
}
ts:操作时间,当前timestamp + 计数器,计数器每秒都被重置
h:操作的全局唯一标识
v:oplog版本信息
op:操作类型
i:插入操作
u:更新操作
d:删除操作 c:执行命令(如createDatabase,dropDatabase)
n:空操作,特殊用途
ns:操作针对的集合
o:操作内容 o2:更新查询条件,仅update操作包含该字段
2.2.2 有三种类型的节点
- PRIMARY 可以查询和新增
- SECONDARY 只能查询不能新增 基于
priority权重可以被选为主节点 - ARBITER 不能查询和新增 不能变为主节点
2.2.3 数据同步
复制集数据同步分为初始化同步和keep复制同步。初始化同步指全量从主节点同步数据,如果Primary节点数据量 比较大同步时间会比较⻓。而keep复制指初始化同步过后,节点之间的实时同步一般是增量同步。
- 初始化同步有以下两种情况触发
- Secondary第一次加入
- Secondary落后的数据量超过了oplog的大小,这样也会被全量复制
MongoDB的Primary节点选举基于心跳触发。一个复制集N个节点中的任意两个节点维持心跳,每个节点维护其他 N-1个节点的状态
心跳检测:
整个集群需要保持一定的通信才能知道哪些节点活着哪些节点挂掉,mongodb节点会向副本集中的其他节点每2秒就会 发送一次pings包,如果其他节点在10秒钟之内没有返回就标示为不能访问。
每个节点内部都会维护一个状态映射表, 表明当前每个节点是什么⻆色、日志时间戳等关键信息。
如果主节点发现自己无法与大部分节点通讯则把自己降级为 secondary只读节点
主节点选举触发的时机:
- 第一次初始化一个复制集
- Secondary节点权重比Primary节点高时,发起替换选举
- Secondary节点发现集群中没有Primary时,发起选举
- Primary节点不能访问到大部分(Majority)成员时主动降级
当触发选举时,Secondary节点尝试将自身选举为Primary。主节点选举是一个二阶段过程+多数派协议
- 第一阶段: 检测自身是否有被选举的资格 如果符合资格会向其它节点发起本节点是否有选举资格的FreshnessCheck,进行同僚 仲裁
- 第二阶段: 发起者向集群中存活节点发送Elect(选举)请求,仲裁者收到请求的节点会执行一系列合法性检查,如果检查通过,则仲裁者(一个复制集中最多50个节点 其中只有7个具有投票权)给发起者投一票。 pv0通过30秒选举锁防止一次选举中两次投票。 pv1使用了terms(一个单调递增的选举计数器)来防止在一次选举中投两次票的情况。
- 多数派协议: 发起者如果获得超过半数的投票,则选举通过,自身成为Primary节点。获得低于半数选票的原因,除了常⻅的网络问 题外,相同优先级的节点同时通过第一阶段的同僚仲裁并进入第二阶段也是一个原因。因此,当选票不足时,会 sleep[0,1]秒内的随机时间,之后再次尝试选举。
2.3 搭建复制集
- 复制三个程序,端口定义为27017,27018,27019,搭建伪集群,文件目录如下
$ tree -L 2
.
├── mongodb-27017
├── bin
└── mongo.conf
├── mongodb-27018
├── bin
└── mongo.conf
└── mongodb-27019
├── bin
└── mongo.conf
- 三个配置文件基本相同,只有端口号的区别,如下
dbpath=/data/mongo/27017
port=27017
bind_ip=0.0.0.0
fork=true
logpath=/data/mongo/logs/27017/mongo.log
replSet=mongoCluster
- 创建对应的data和logs日志目录
data/mongo
├── 27017
├── 27018
├── 27019
└── logs
- 启动三个实例
$ mongodb-27017/bin/mongod -f mongodb-27017/mongo.conf
$ mongodb-27018/bin/mongod -f mongodb-27018/mongo.conf
$ mongodb-27019/bin/mongod -f mongodb-27019/mongo.conf
- 初始化节点-进入到一个mongo节点中执行
var cfg={"_id":"mongoCluster","protocolVersion":1,"members":[{"_id":0,"host":"10.0.24.3:27017"},{"_id":1,"host":"10.0.24.3:27018"},{"_id":2,"host":"10.0.24.3:27019"}]}
rs.initiate(cfg)
rs.status()
节点的动态增删
- 增
rs.add("ip:port") - 删
rs.remove("ip:port")
- 增
加入仲裁节点(可不加)
启动一个仲裁实例27020,然后在复制集中执行
mongoCluster:PRIMARY> rs.addArb("10.0.24.3:27020") { "ok" : 1, "$clusterTime" : { "clusterTime" : Timestamp(1670917290, 1), "signature" : { "hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="), "keyId" : NumberLong(0) } }, "operationTime" : Timestamp(1670917290, 1) }
2.4 复制集成员的配置参数
对应
var cfg=...
| 参数字段 | 类型书名 | 取值 | 说明 |
|---|---|---|---|
| _id | 整数 | _id:0 | 复制集中的标示 |
| host | 字符串 | host:"主机:端口" | 节点主机名 |
| arbiterOnly | 布尔值 | arbiterOnly:true | 是否为仲裁(裁判)节点 |
| priority | 整数 | priority=0..n | 默认1,是否有资格变成主节点, 取值范围0-1000,0 远不会变成主节点 |
| hidden | 布尔值 | 0或1 | 隐藏,权重必须为0,才可以设置 |
| votes | 整数 | 0或1 | 投票,是否为投票节点,0 不投票,1投票 |
| slaveDelay | 整数 | slaveDelay=3600 | 从库的延迟多少秒 |
| buildIndexes | 布尔值 | 0或1 | 主库的索引,从库也创建,_id索引无效 |
version: '3.3'
services:
mongo_rs_1:
env_file:
- .env
image: mongo:4.2
container_name: mongo_rs_1
restart: always
ports:
- ${MONGO_RS_1_PORT}:27017
volumes:
- ${PWD}/rs1/db:/data/db
- ${PWD}/rs1/log:/var/log/mongodb
- ${PWD}/rs1/config:/etc/mongo
command:
- --replSet
- rs
mongo_rs_2:
image: mongo:4.2
container_name: mongo_rs_2
restart: always
ports:
- ${MONGO_RS_2_PORT}:27017
volumes:
- ${PWD}/rs2/db:/data/db
- ${PWD}/rs2/log:/var/log/mongodb
- ${PWD}/rs2/config:/etc/mongo
command:
- --replSet
- rs
mongo_rs_3:
image: mongo:4.2
container_name: mongo_rs_3
restart: always
ports:
- ${MONGO_RS_3_PORT}:27017
volumes:
- ${PWD}/rs3/db:/data/db
- ${PWD}/rs3/log:/var/log/mongodb
- ${PWD}/rs3/config:/etc/mongo
command:
- --replSet
- rs
mongo_rs_init:
image: mongo:4.2
depends_on:
- mongo_rs_1
- mongo_rs_2
- mongo_rs_3
restart: on-failure:5
command:
- mongo
- mongodb://mongo_rs_1:27017/admin
- --eval
- 'rs.initiate({ _id: "rs", members: [{_id:1,host:"mongo_rs_1:27017"},{_id:2,host:"mongo_rs_2:27017"},{_id:3,host:"mongo_rs_3:27017"}]})'
# rs.secondaryOk()
3. 分片集群
分片(sharding)是MongoDB用来将大型集合水平分割到不同的服务器(或者复制集)上采用的方法,不需要功能强大的大型计算机就可以存储更多的数据,以处理更大的负载
3.1 为什么要分片
- 存储容量需求超出单机磁盘容量
- 活跃的数据集超出单机内存容量,导致很多请求都要从磁盘读取数据,影响性能
- IOPS超出单个MongoDB节点的服务能力,随着数据的增⻓,单机实例的瓶颈会越来越明显
- 副本集具有节点数量限制
垂直扩展:增加更多的CPU和存储资源来扩展容量
水平扩展:将数据集分布在多个服务器上。水平扩展即分片
3.2 分片的工作原理
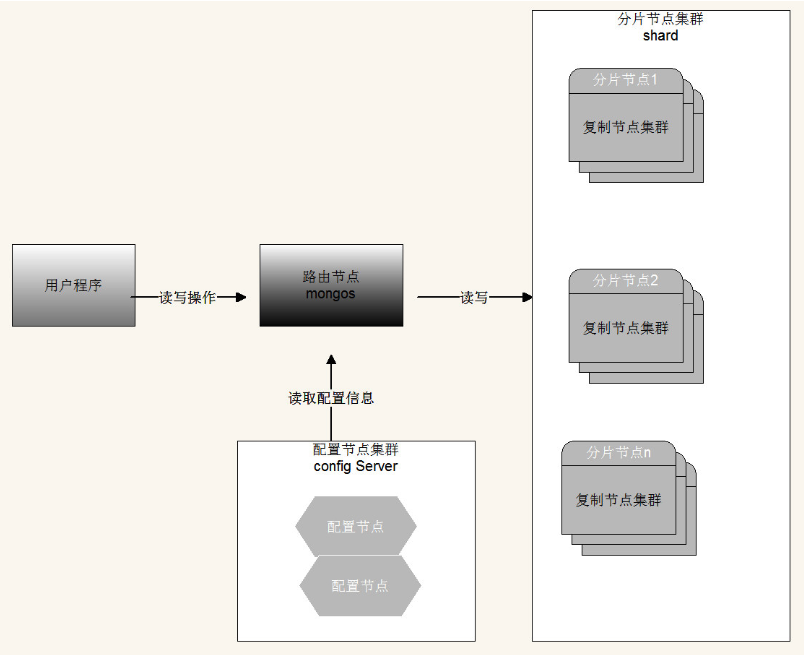
分片集群由三个服务组成:
Shards Server: 每个shard由一个或多个mongod进程组成,用于存储数据Router Server: 数据库集群的请求入口,所有请求都通过Router(mongos)进行协调,不需要在应用程序添加一个 路由选择器,Router(mongos)就是一个请求分发中心它负责把应用程序的请求转发到对应的Shard服务器上Config Server: 配置服务器。存储所有数据库元信息(路由、分片)的配置
相关概念
片键(shard key)
为了在数据集合中分配文档,MongoDB使用分片主键分割集合
区块 (chunk)
在一个shard server内部,MongoDB还是会把数据分为chunks,每个chunk代表这个shard server内部一部 分数据。MongoDB分割分片数据到区块,每一个区块包含基于分片主键的左闭右开的区间范围
分片策略
范围分片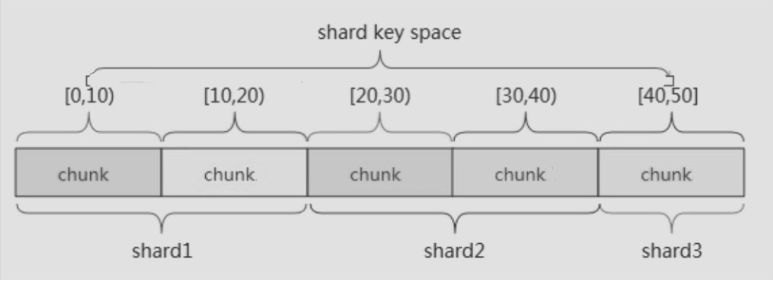
范围分片是基于分片主键的值切分数据,每一个区块将会分配到一个范围
范围分片适合满足在一定范围内的查找,例如查找X的值在[20,30)之间的数据,mongo 路由根据Config server中存储的元数据,可以直接定位到指定的shard的Chunk中
缺点: 如果shard key有明显递增(或者递减)趋势,则新插入的文档多会分布到同一个chunk,无法扩展写的能力
HASH分片
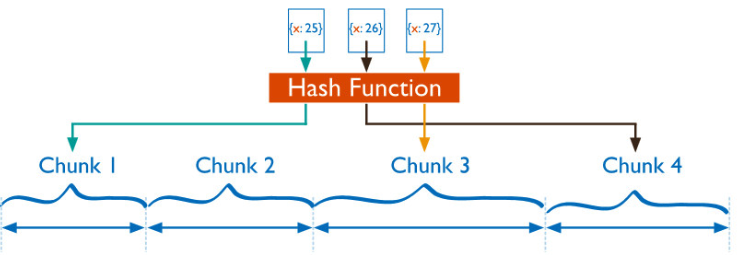
Hash分片是计算一个分片主键的hash值,每一个区块将分配一个范围的hash值
Hash分片与范围分片互补,能将文档随机的分散到各个chunk,充分的扩展写能力,弥补了范围分片的不足,
缺点:不能高效的服务范围查询,所有的范围查询要分发到后端所有的Shard才能找出满足条件的文档
组合片键 数据库中没有比较合适的片键供选择,或者是打算使用的片键基数太小(即变化少如星期只有7天可变化), 可以选另一个字段使用组合片键,甚至可以添加冗余字段来组合。一般是粗粒度+细粒度进行组合。
合理选择shard key
无非从两个方面考虑,数据的查询和写入,最好的效果就是数据查询时能命中更少的分片,数据写入时能够随机的写入每个分片,关键在于如何权衡性能和负载。
3.3 搭建分片集群
结构
$ tree -L 1 .
.
├── config-17017
├── config-17018
├── config-17019
├── mongodb-linux-x86_64-rhel70-4.2.23.tgz
├── route-27017
├── shard-1-37017
├── shard-1-37018
├── shard-1-37019
├── shard-2-47017
├── shard-2-47018
├── shard-2-47019
├── shard-3-57017
├── shard-3-57018
├── shard-3-57019
├── start-config.sh
├── start-mongo-all.sh
├── start-route.sh
├── start-shard.sh
└── stop-mongo-all.sh
配置节点
$ cat config-17017/mongo.conf
dbpath=/data/mongo/shard/config/config1
port=17017
bind_ip=0.0.0.0
fork=true
logpath=/data/mongo/shard/config/config1/logs/config.log
logappend=true
# 配置服务器
configsvr=true
# 配置服务器副本集名
replSet=configsvr
进行配置
use admin
var cfg = {"_id":"configsvr",
"members":[
{"_id":1,"host":"10.0.24.3:17017"},
{"_id":2,"host":"10.0.24.3:17018"},
{"_id":3,"host":"10.0.24.3:17019"},
]}
rs.initiate(cfg)
分片集群节点
$ cat shard-1-37017/mongo.conf
dbpath=/data/mongo/shard/1/37017
port=37017
bind_ip=0.0.0.0
fork=true
logpath=/data/mongo/shard/1/37017/logs/mongo.log
replSet=shard1
shardsvr=true
每个集群都进行配置
var cfg = {
"_id":"shard1",
"protocolVersion":1,
"members":[
{"_id":1,"host":"10.0.24.3:37017"},
{"_id":2,"host":"10.0.24.3:37018"},
{"_id":3,"host":"10.0.24.3:37019"},
]
};
rs.initiate(cfg)
rs.status()
路由节点
$ cat route-27017/mongo.conf
port=27017
bind_ip=0.0.0.0
fork=true
logpath=/data/mongo/shard/route/27017/logs/mongo.log
configdb=configsvr/10.0.24.3:17017,10.0.24.3:17018,10.0.24.3:17019
依次启动配置、分片集群、路由节点(配置需要在启动后操作)
$ cat start-config.sh
#!/bin/bash
echo "mongo shard config"
for port in {17017..17019}
do
config-${port}/bin/mongod -f config-${port}/mongo.conf
echo "${port} started."
done
---
$ cat start-route.sh
#!/bin/bash
echo "mongo shard route"
for port in {27017..27017}
do
route-${port}/bin/mongos -f route-${port}/mongo.conf
echo "${port} started."
done
---
$ cat start-route.sh
#!/bin/bash
echo "mongo shard route"
for port in {27017..27017}
do
route-${port}/bin/mongos -f route-${port}/mongo.conf
echo "${port} started."
done
进入到路由节点,添加集群
sh.addShard("shard1/10.0.24.3:37017,10.0.24.3:37018,10.0.24.3:37019")
sh.addShard("shard2/10.0.24.3:47017,10.0.24.3:47018,10.0.24.3:47019")
sh.addShard("shard3/10.0.24.3:57017,10.0.24.3:57018,10.0.24.3:57019")
sh.status()
开启数据库和集合分片
sh.enableSharding("数据库名称")
sh.shardCollection("数据库名称.集合名称",{"片键名称如name":索引说明})