字符串
字符串
String简介
有哪些命令
数据结构
- 如果value是64位有符号整数,Redis保存为8字节的Long类型整数(int编码方式)
- 如果value中包含字符串,Redis使用SDS(Simple Dynamic String)结构体保存
数据结构
源码中定义如下结构体(包括sdshdr5,sdshdr8,sdshdr16,sdshdr32,sdshdr64)
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* buf的已用长度,占1个字节 */
uint8_t alloc; /* buf的实际分配长度,占1个字节, 排除了header和null终止符 */
unsigned char flags; /* SDS类型,和SDS_TYPE_MASK计算出是sdshdr5/8/16/32/64 */
char buf[]; /* 实际数据 */
};
其中__attribute__ ((__packed__))表示 告诉编译器在对结构体进行内存对齐时不要进行字节对齐填充,采用紧凑的方式分配内存。默认如果变量5个字节,不够8字节也会分配8字节,使用后只有5个字节。
SDS关键函数
相关源码实现: sds.c
| 函数 | 作用 | 时间复杂度 |
|---|---|---|
sdsnew | 创建一个包含给定 C 字符串的 SDS 。 | O(N) , N 为给定 C 字符串的长度。 |
sdsempty | 创建一个不包含任何内容的空 SDS 。 | O(1) |
sdsfree | 释放给定的 SDS 。 | O(1) |
sdslen | 返回 SDS 的已使用空间字节数。 | 这个值可以通过读取 SDS 的 len 属性来直接获得, 复杂度为 O(1) 。 |
sdsavail | 返回 SDS 的未使用空间字节数。 | 这个值可以通过读取 SDS 的 free 属性来直接获得, 复杂度为 O(1) 。 |
sdsdup | 创建一个给定 SDS 的副本(copy)。 | O(N) , N 为给定 SDS 的长度。 |
sdsclear | 清空 SDS 保存的字符串内容。 | 因为惰性空间释放策略,复杂度为 O(1) 。 |
sdscat | 将给定 C 字符串拼接到 SDS 字符串的末尾。 | O(N) , N 为被拼接 C 字符串的长度。 |
sdscatsds | 将给定 SDS 字符串拼接到另一个 SDS 字符串的末尾。 | O(N) , N 为被拼接 SDS 字符串的长度。 |
sdscpy | 将给定的 C 字符串复制到 SDS 里面, 覆盖 SDS 原有的字符串。 | O(N) , N 为被复制 C 字符串的长度。 |
sdsgrowzero | 用空字符将 SDS 扩展至给定长度。 | O(N) , N 为扩展新增的字节数。 |
sdsrange | 保留 SDS 给定区间内的数据, 不在区间内的数据会被覆盖或清除。 | O(N) , N 为被保留数据的字节数。 |
sdstrim | 接受一个 SDS 和一个 C 字符串作为参数, 从 SDS 左右两端分别移除所有在 C 字符串中出现过的字符。 | O(M*N) , M 为 SDS 的长度, N 为给定 C 字符串的长度。 |
sdscmp | 对比两个 SDS 字符串是否相同。 | O(N) , N 为两个 SDS 中较短的那个 SDS 的长度。 |
为什么使用SDS,而不是char*
Redis为什么使用SDS,而不是char*
背景:C语言中使用char字符数组来实现字符串,char指针指向字符数组起始位置,\0表示字符串的结尾
为什么不用char*字符数组(因/0带来的问题):
- 不能存储任意格式数据(例如二进制)
- 操作字符串获取长度需要遍历到\0,效率不高 O(N)
为什么使用SDS(SDS的优势)(需要掌握SDS结构):
- len + buf 1.1 由于使用len属性表示长度,可以规避\0的问题,即能存储二进制(buf[]),获取长度直接使用属性值,O(1) 1.2 拼接字符串会检查空间大小是否满足,避免缓冲区溢出
- flags + alloc +len 2.1 有多种类型的SDS(flags表示类型,len alloc区分长度),存储长度不同的字符串 2.2 attribute ((packed))编译优化,采用紧凑方式分配内存 2.3 字符串内部编码优化,有int raw embstr三种
个人理解:从“降本增效”的角度来看(降低内存使用,增加操作效率)
- 降本:多种结构头存储不同大小字符串,紧凑型分配内存,内部编码优化
- 增效:使用len提升效率,避免遍历到\0,基于长度的操作(如复制、追加)提升效率
- 功能上可以存储二进制数据
引用《Redis设计与实现》中的图: 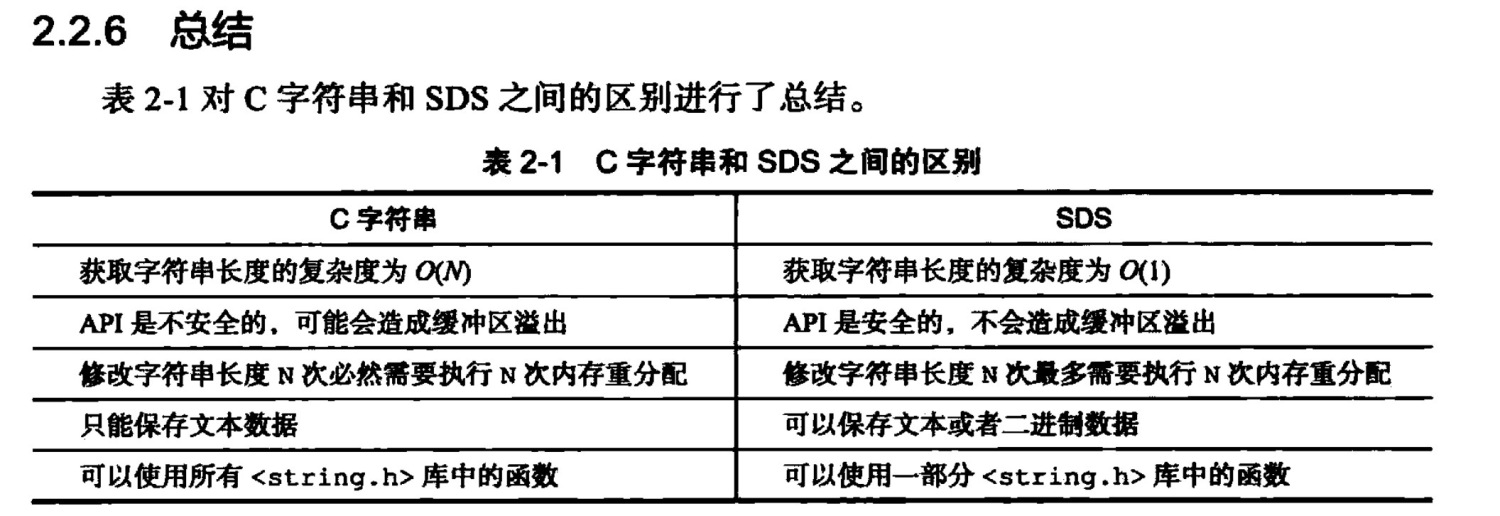
占用内存高
Redis的String占用内存高的问题
极客时间:Redis核心技术与实战:11 | “万金油”的String,为什么不好用了?
由于RedisObject,和SDS中属性的元数据存储,在存储较长数据时会有更多的额外内存空间开销 ,内存增大会导致因为生成RDB而变慢。
可以使用压缩列表(ziplist)数据结构节省内存(用一系列连续的 entry 保存数据),基于ziplist的实现数据类型有:Hash,List,SortedSet。
如果使用Hash则可以采用二级编码的方式(将前一部分key做为key,后一部分key作为field), 需要注意,Redis中的Hash的两种底层结构是压缩列表和哈希表,需要将key的长度控制在压缩列表结构上(例如将1101000060中的前7位1101000作为Hash的key,060作为field)
Hash阈值配置项: hash-max-ziplist-entries:用压缩列表保存时哈希集合中的最大元素个数 hash-max-ziplist-value:用压缩列表保存时哈希集合中单个元素的最大长度
嵌入式字符串(embstr)的条件是44字节
为什么SDS判断是否使用嵌入式字符串(embstr)的条件是44字节
embstr将RedisObject对象头和SDS对象连续存一起,使用一次malloc分配。raw需要两次malloc分配,两个对象头在内存地址上一般不连续。 内存分配子jmalloc最少分配32字节空间(只会分配2的幂),当字符串再长一点就会分配64字节。如果超过64字节,将使用raw形式存储。
条件是44字节的原因是redisObject和sdshdr结构体元数据和字符数组结束符占了20个字节(64-20=44)
typedef struct redisObject {
unsigned type:4; // 4 bits
unsigned encoding:4; // 4 bits
unsigned lru:LRU_BITS; // 24 bits
int refcount; // 4 bytes
void *ptr; // 8 bytes
} robj;
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; // 1 byte
uint8_t alloc; // 1 byte
unsigned char flags; // 1 byte
char buf[]; // 44 bytes + 1 byte(结尾\0)
};
/* Create a string object with EMBSTR encoding if it is smaller than
* OBJ_ENCODING_EMBSTR_SIZE_LIMIT, otherwise the RAW encoding is
* used.
*
* The current limit of 44 is chosen so that the biggest string object
* we allocate as EMBSTR will still fit into the 64 byte arena of jemalloc. */
#define OBJ_ENCODING_EMBSTR_SIZE_LIMIT 44
robj *createStringObject(const char *ptr, size_t len) {
if (len <= OBJ_ENCODING_EMBSTR_SIZE_LIMIT)
return createEmbeddedStringObject(ptr,len);
else
return createRawStringObject(ptr,len);
}
扩容策略
Redis中String的扩容策略
if (newlen < SDS_MAX_PREALLOC)
newlen *= 2;
else
newlen += SDS_MAX_PREALLOC;
字符串长度小于1M: n = 2 * n, 字符串长度大于1M: n = n + 1